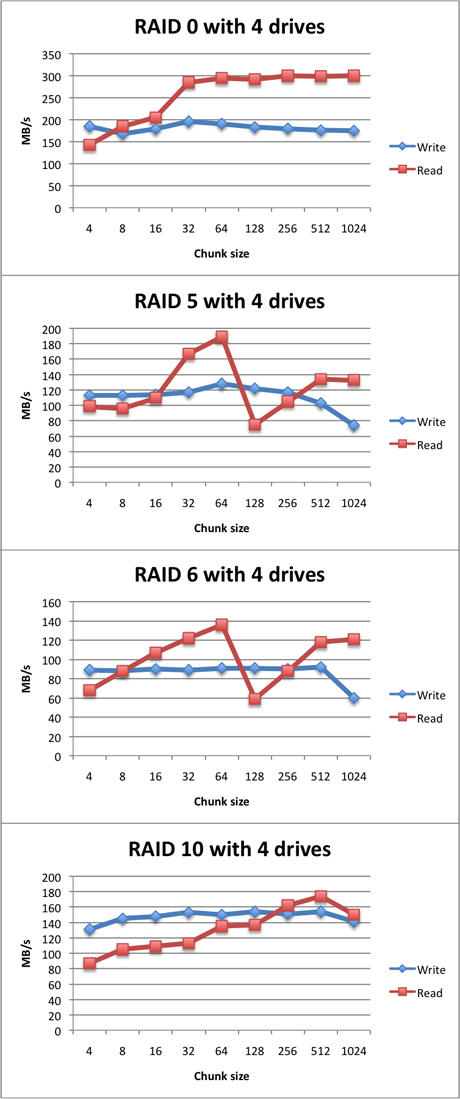
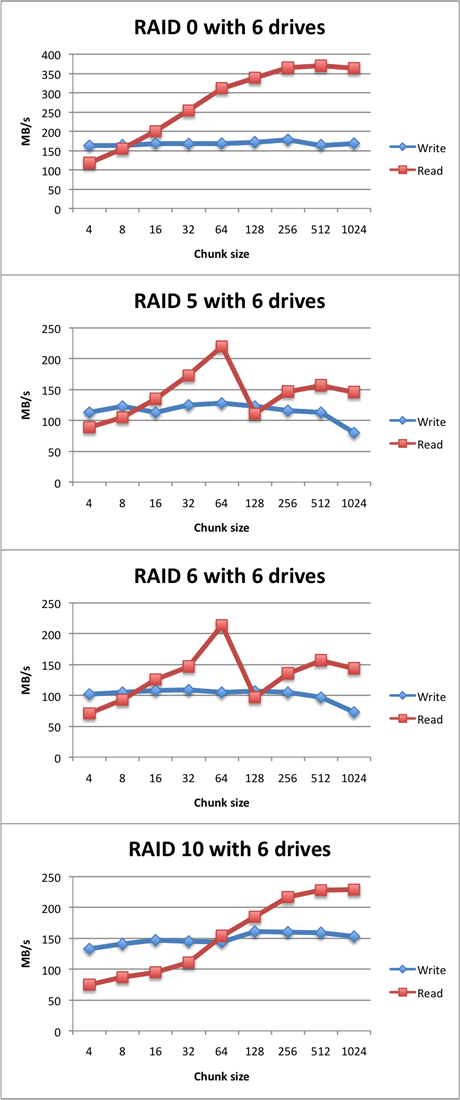
Storage is cheap. Lots of storage with 10+ hard drives is still cheap. Running 10 drives increases the risk of a drive failure tenfold. So often RAID 5 is used to keep your data up and running if one single disks fails.
But disks are so cheap and storage arrays are getting so vast that RAID 5 does not cut it anymore. With larger arrays, the risk of a second drive failure while your failed array is in a degraded state (a drive already failed and the array is rebuilding or waiting for a replacement), is serious.
RAID 6 uses two parity disks, so you loose two disks of capacity, but the rewards in terms of availability are very large. Especially regarding larger arrays.
I found a blog posting that showed the results on a big simulation run on the reliability of various RAID setups. One picture of this post is important and it is shown below. This picture shows the risk of the entire RAID array failing before 3 years.

From this picture, the difference between RAID 5 and RAID 6 regarding reliability (availability) is astounding. There is a strong relation with the size of the array (number of drives) and the increased risk that more than one drive fails, thus destroying the array. Notice the strong contrast with RAID 6.
Even with a small RAID 5 array of 6 disks, there is already a 1 : 10 chance that the array will fail within 3 years. Even with 60+ drives, a RAID 6 array never comes close to a risk like that.
- Creating larger RAID 5 arrays beyond 8 to 10 disks means there is a 1 : 8 to 1
- 5 chance that you will have to recreate the array and restore the contents from backup (which you have of course).
I have a 20 disk RAID 6 running at home. Even with 20 disks, the risk that the entire array fails due to failure of more than 2 disks is very small. It is more likely that I lose my data due to failure of a RAID controller, motherboard or PSU than dying drives.
There are more graphs that are worth viewing, so take a look at this excelent blog post.