Introduction
When configuring a Linux RAID array, the chunk size needs to get chosen. But what is the chunk size?
When you write data to a RAID array that implements striping (level 0, 5, 6, 10 and so on), the chunk of data sent to the array is broken down in to pieces, each part written to a single drive in the array. This is how striping improves performance. The data is written in parallel to the drive.
The chunk size determines how large such a piece will be for a single drive. For example: if you choose a chunk size of 64 KB, a 256 KB file will use four chunks. Assuming that you have setup a 4 drive RAID 0 array, the four chunks are each written to a separate drive, exactly what we want.
This also makes clear that when choosing the wrong chunk size, performance may suffer. If the chunk size would be 256 KB, the file would be written to a single drive, thus the RAID striping wouldn't provide any benefit, unless manny of such files would be written to the array, in which case the different drives would handle different files.
In this article, I will provide some benchmarks that focus on sequential read and write performance. Thus, these benchmarks won't be of much importance if the array must sustain a random IO workload and needs high random iops.
Test setup
All benchmarks are performed with a consumer grade system consisting of these parts:
Processor: AMD Athlon X2 BE-2300, running at 1.9 GHz.
RAM: 2 GB
Disks: SAMSUNG HD501LJ (500GB, 7200 RPM)
SATA controller: Highpoint RocketRaid 2320 (non-raid mode)
Tests are performed with an array of 4 and an array of 6 drives.
-
All drives are attached to the Highpoint controller. The controller is not used for RAID, only to supply sufficient SATA ports. Linux software RAID with mdadm is used.
-
A single drive provides a read speed of 85 MB/s and a write speed of 88 MB/s
-
The RAID levels 0, 5, 6 and 10 are tested.
-
Chunk sizes starting from 4K to 1024K are tested.
-
XFS is used as the test file system.
-
Data is read from/written to a 10 GB file.
-
The theoretical max through put of a 4 drive array is 340 MB/s. A 6 drive array should be able to sustain 510 MB/s.
About the data:
-
All tests have been performed by a Bash shell script that accumulated all data, there was no human intervention when acquiring data.
-
All values are based on the average of five runs. After each run, the RAID array is destroyed, re-created and formatted.
-
For every RAID level + chunk size, five tests are performed and averaged.
-
Data transfer speed is measured using the 'dd' utility with the option bs=1M.
Test results
Results of the tests performed with four drives:
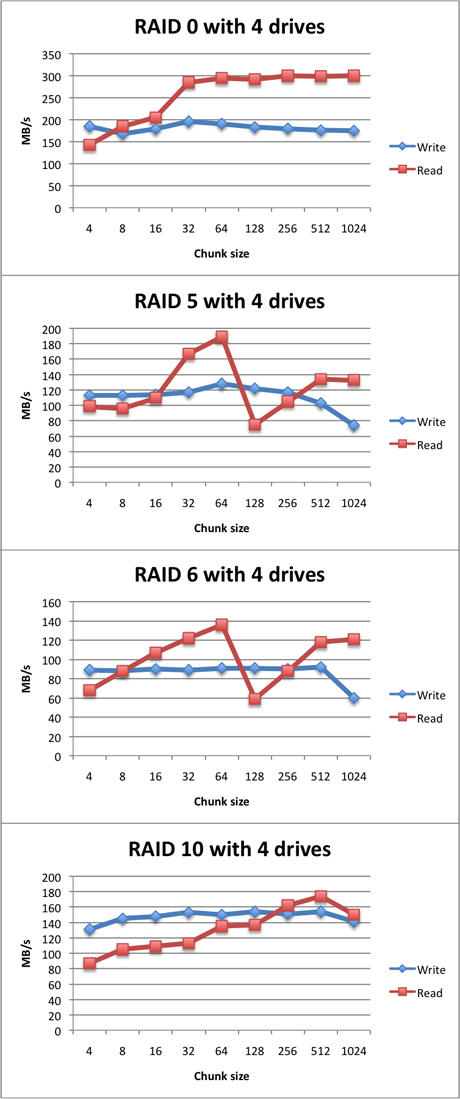
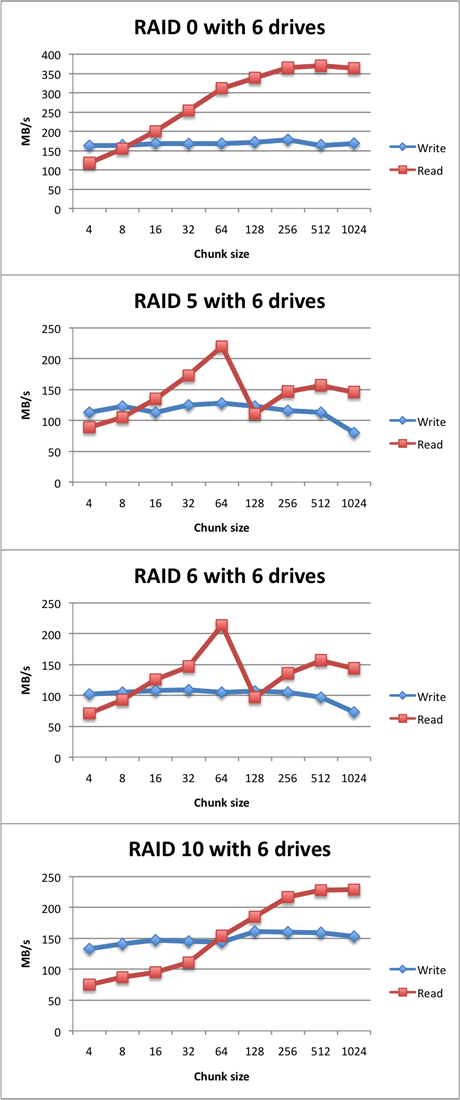
Test results with six drives:
Analysis and conclusion
Based on the test results, several observations can be made. The first one is that RAID levels with parity, such as RAID 5 and 6, seem to favor a smaller chunk size of 64 KB.
The RAID levels that only perform striping, such as RAID 0 and 10, prefer a larger chunk size, with an optimum of 256 KB or even 512 KB.
It is also noteworthy that RAID 5 and RAID 6 performance don't differ that much.
Furthermore, the theoretical transfer rates that should be achieved based on the performance of a single drive, are not met. The cause is unknown to me, but overhead and the relatively weak CPU may have a part in this. Also, the XFS file system may play a role in this. Overall, it seems that on this system, software RAID does not seem to scale well. Since my big storage monster (as seen on the left) is able to perform way better, I suspect that it is a hardware issue.
because the M2A-VM consumer-grade motherboard can't go any faster.
