Personally I have a weakness for big-ass storage. Say 'petabyte' and I'm interested. So I was thinking about how you would setup a large, scalable storage infrastructure. How should such a thing work?
Very simple: you should be able just to add hosts with some bad-ass huge RAID arrays attached to them. Maybe even not that huge, say 8 TB RAID 6 arrays or maybe bigger. You use these systems as building blocks to create a single and very large storage space. And then there is one additional requirement: as the number of these building blocks increase, you must be able to loose some and not loose data or availability. You should be able to continue operations without one or two of those storage building blocks before you would loose data and/or availability. Like RAID 5 or 6 but then over server systems instead of hard drives.
The hard part is in connecting all this separate storage to one virtual environment. A solution to this problem is Lustre.
Lustre is a network clustering filesystem. What does that mean? You can use Lustre to create a scalable storage platform. A single filesystem that can grow to multiple Petabytes. Lustre is deployed within production environments at large scale sites involving some of the fastest and largest computer clusters. Luster is thus something to take seriously.
Lustre stores all metadata about files on a separate MetaDataServer (MDS). Al actual file data is stored on Object Storage Targets (OSTs). These are just machines with one or more big RAID arrays (or simple disks) attached to them. The OSTs are not directly accessible by clients, but through an Object Storage Server (OSS). The data stored within a file can be striped over multiple OSTs for performance reasons. A sort of network RAID 0.
Lustre does not only allow scaling up to Petabytes of storage, but allows also a parallel file transfer performance in excess of 100 GB/s. How you like them apples? That is just wicked sick.
Just take a look at this diagram about how Lustre operates:
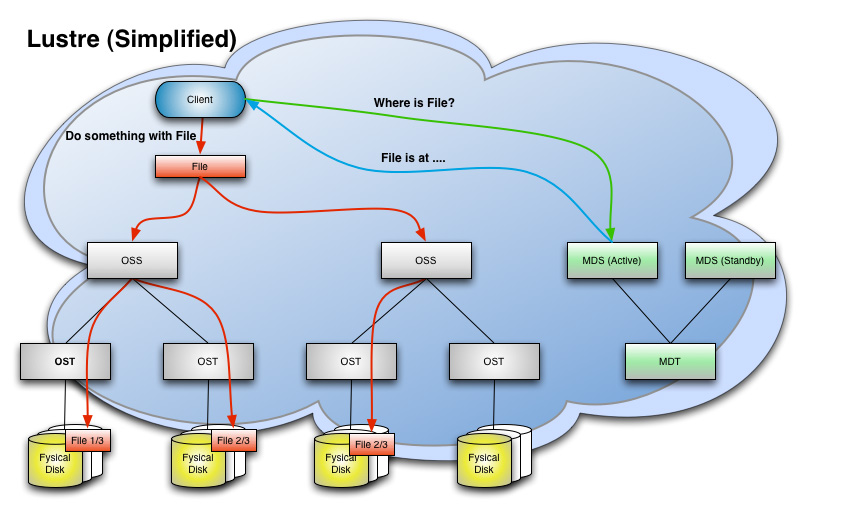
I'm not going into the details about Lustre. I want to discuss a shortcoming that may pose a serious risk of data loss: if you loose a single OST with any attached storage, you will lose all data stored on that OST.
Lustre cannot cope with the loss of a single OST! Even if you buy fully redundant hardware, with double RAID controllers, ECC memory, double PSU, etc, even then, if the motherboard gets fried, you will loose data. Surely not everything, but let's say 'just' 8 TB maybe?
I guess the risk is assumed to be low, because of the wide scale deployment of Lustre. Deployed by people who actually use it and have way more experience and knowledge than me about this whole stuff. So maybe I'm pointing out risks that are just very small. But I have seen server systems fail this bad as described. I don't think the risk, especially at this scale, is not that small.
I am certainly not the first to point out this risk.
The solution for Lustre to became truly awesome is to implement some kind of network based RAID 6 striping so you could loose one or even two OSTs and not have any impact on availability except maybe for performance. But it doesn't (yet).
This implies that you have to create your OSTs super-reliable, which would be very expensive (does not scale). Or have some very high-capacity backup solution, which would be able to restore some data. But you would have downtime.
So my question to you is: is there an actual scalable filesystem as Lustre that actually is capable of withstanding the failure of a single storage building block? If you have something to point out, please do.
BTW: please note that the loss of an OSS can be overcome because another OSS can take over the OSTs of a failed OSS.

