Introduction
The goal of this blogpost is to help you better understand storage performance. I want to discuss some fundamentals that are true regardless of your particular needs.
This will help you better reason about storage and may provide a scaffolding for further learning.
If you run your applications / workloads entirely in the cloud, this information may feel antiquated or irrelevant.
However, since the cloud is just somebody else's compute and storage, knowledge about storage may still be relevant. Cloud providers expose storage performance metrics for you to monitor and this may help to make sense of them.
Concepts
I/O
An I/O is a single read/write request. That I/O is issued to a storage medium (like a hard drive or solid state drive).
It can be a request to read a particular file from disk. Or it can be a request to write some data to an existing file. Reading or writing a file can result in multiple I/O requests.
I/O Request Size
The I/O request has a size. The request can be small (like 1 Kilobyte) or large (several megabytes). Different application workloads will issue I/O operations with different request sizes. The I/O request size can impact latency and IOPS figures (two metrics we will discuss shortly).
IOPS
IOPS stands for I/O Operations Per Second. It is a performance metric that is used (and abused) a lot in the world of storage. It tells us how many I/O requests per second can be handled by the storage (for a particular workload).
Warning: this metric is meaningless without a latency figure. We will discuss latency shortly.
Bandwidth or throughput
If you multiply the IOPS figure with the (average) I/O request size, you get the bandwidth or throughput. We state storage bandwidth mostly in Megabytes and Gigabytes per second.
To give you an example: if we issue a workload of 1000 IOPS with a request size of 4 Kilobytes, we will get a throughput of 1000 x 4 KB = 4000 KB. This is about ~4 Megabytes per second.
Latency
Latency is the time it takes for the I/O request to be completed. We start our measurement from the moment the request is issued to the storage layer and stop measuring when either we get the requested data, or get confirmation that the data is stored on disk.
Latency is the single most important metric to focus on when it comes to storage performance, under most circumstances.
For hard drives, an average latency somewhere between 10 to 20 ms is considered acceptable (20 ms is the upper limit).
For solid state drives, depending on the workload it should never reach higher than 1-3 ms. In most cases, workloads will experience less than 1ms latency numbers.
IOPS and Latency
This is a very important concept to understand. The IOPS metric is meaningless without a statement about latency. You must understand how long each I/O operation will take because latency dictates the responsiveness of individual I/O operations.
If a storage solution can reach 10,000 IOPS but only at an average latency of 50 ms that could result in very bad application performance. If we want to hit an upper latency target of 10 ms the storage solution may only be capable of 2,000 IOPS.
For more details on this topic I would recommend this blog and this blog.
Access Patterns
Sequential access
An example of a sequential data transfer is copying a large file from one hard drive to another. A large number of sequential (often adjacent) datablocks is read from the source drive and written to another drive. Backup jobs also cause sequential access patterns.
In practice this access pattern shows the highest possible throughput.
Hard drives have it easy as they don't have to spend much time moving their read/write heads and can spend most time reading / writing the actual data.
Random access
I/O requests are issued in a seemingly random pattern to the storage media. The data could be stored all over various regions on the storage media. An example of such an access pattern is a heavy utilised database server or a virtualisation host running a lot of virtual machines (all operating simultaneously).
Hard drives will have to spend a lot of time moving their read/write heads and can only spend little time transferring data. Both throughput and IOPS will plummet (as compared to a sequential access pattern).
In practice, most common workloads, such as running databases or virtual machines, cause random access patterns on the storage system.
Queue depth
The queue depth is a number between 1 and ~128 that shows how many I/O requests are queued (in-flight) on average. Having a queue is beneficial as the requests in the queue can be submitted to the storage subsystem in an optimised manner and often in parallel. A queue improves performance at the cost of latency.
If you have some kind of storage performance monitoring solution in place, a high queue depth could be an indication that the storage subsystem cannot handle the workload. You may also observe higher than normal latency figures. As long as latency figures are still within tolerable limits, there may be no problem.
Storage Media Performance characteristics
Hard drives
Hard drives (HDDs) are mechanical devices that resemble a record player.
They have an arm with a read/write head and the data is stored on (multiple) platters.

Hard drives have to physically move read/write heads to fulfil read/write requests. This mechanical nature makes them relatively slow as compared to solid state drives (which we will cover shortly).
Especially random access workloads cause hard drives to spend a lot of time on moving the read/write head to the right position at the right time, so less time is available for actual data transfers.
The most important thing to know about hard drives is that from a performance perspective (focussing on latency) higher spindle speeds reduce the average latency.
| Rotational Speed (RPM) | Access Latency(ms) | IOPS |
|---|---|---|
| 5400 | 17-18 | 50-60 |
| 7200 | 12-13 | 75-85 |
| 10,000 | 7-8 | 120-130 |
| 15,000 | 5-6 | 150-180 |
Because the latency of individual I/O requests is lower the drives with a higher RPM, you can issue more of such requests in the same amount of time. That's why the IOPS figure also increases.
Latency and IOPS of an older Western Digital Velociraptor 10,000 RPM drive:
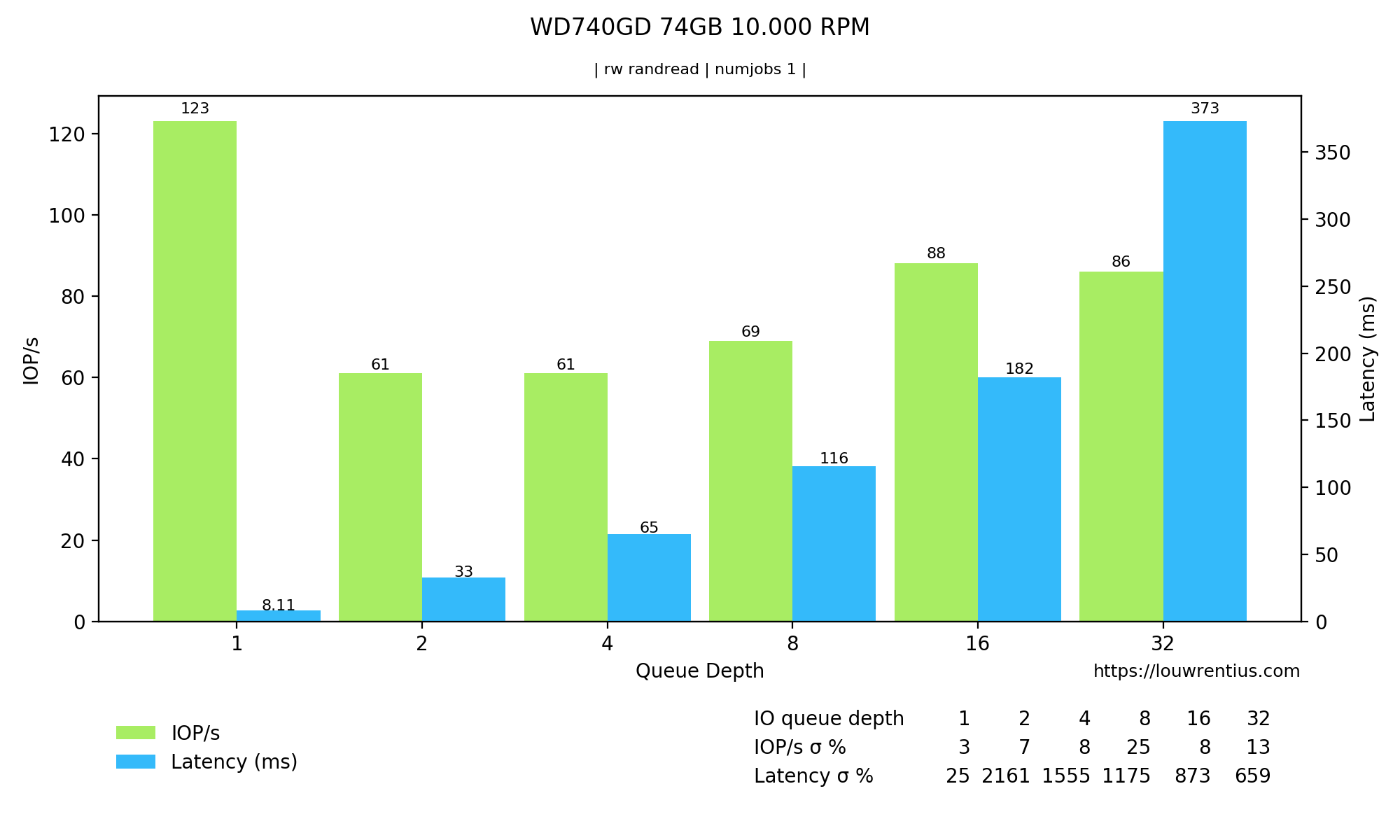 Notice the latency and IOPS in the Queue Depth = 1 column.
Notice the latency and IOPS in the Queue Depth = 1 column.
Source used to validate my own research.
Regarding sequential throughput we can state that fairly old hard drives can sustain throughputs of 100-150 megabytes per second. More modern hard drives with higher capacities can often sustain between 200 - 270 megabytes per second.
An important note: sequential transfer speeds are not constant and depend on the physical location of the data on the hard drive platters. As a drive fills up, throughput diminishes. Throughput can drop more than fifty percent! 1.
So if you want to calculate how long it will take to transfer a particular (large) dataset, you need to take this into account.
Solid State Drives
Solid state drives (SSDs) have no moving parts, they are based on flash memory (chips). SSDs can handle I/O much faster and thus show significantly lower latency.

Whereas we measure the average I/O latency of HDDs in milliseconds (a thousand of a second) we measure the latency of SSD I/O operations in microseconds (a millionth of a second).
Because of this reduced latency per I/O request, SSDs outperform HDDs in every conceivable way. Even a cheap consumer SSD can at least sustain about 5000+ IOPS with only a 0.15 millisecond (150 microseconds) latency. That latency is about 40x better than the best latency of an enterprise 15K RPM hard drive.
Solid state drives can often handle I/O requests in parallel. This means that larger queue depths with more I/O requests in flight can show significantly higher IOPS with a limited (but not insignificant) increase in latency.
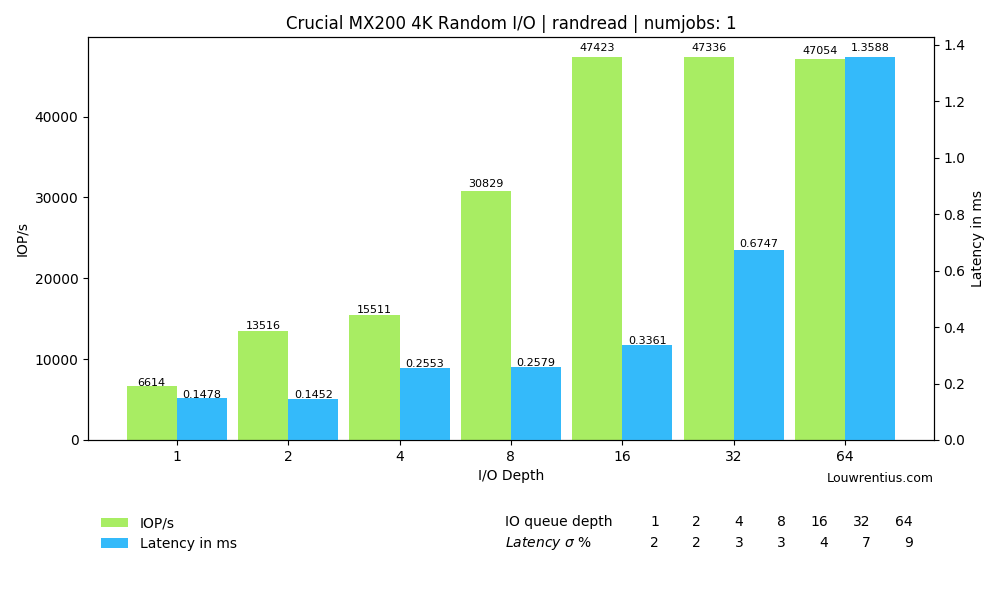 The random I/O performance of an older SATA consumer SSD
The random I/O performance of an older SATA consumer SSD
More modern enterprise SSDs show better latency and IOPS. The SATA interface seems the main bottleneck.
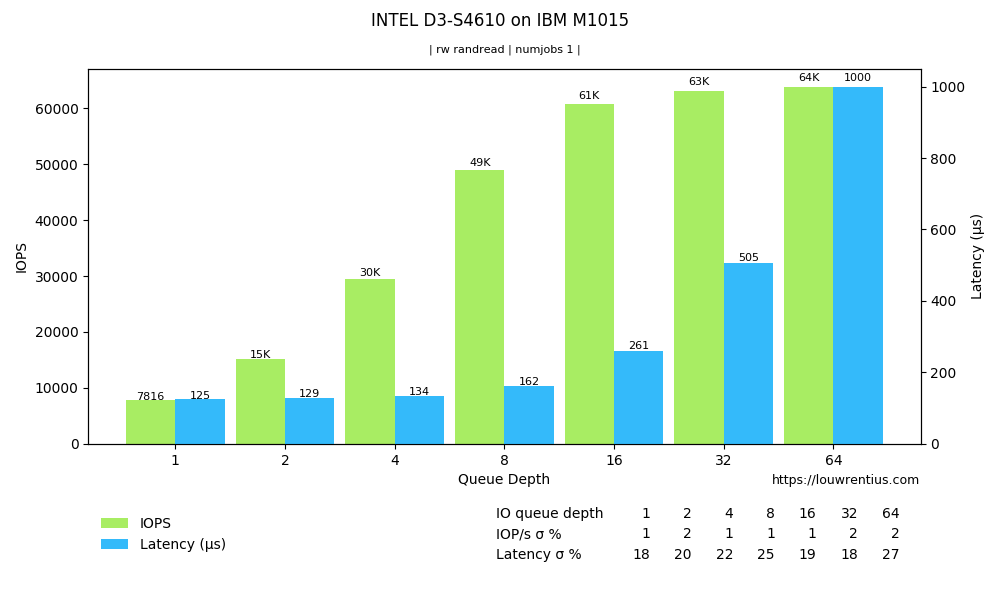 The random I/O performance of an enterprise SATA SSD
The random I/O performance of an enterprise SATA SSD
SSDs perform better than HDDs across all relevant metrics except price in relation to capacity.
Important note: SSDs are not well-suited for archival storage of data. Data is stored as charges in the chips and those charges can diminish over time. It's expected that even hard drives are better suited for offline archival purposes although the most suitable storage method would probably be tape.
SSD actual performance vs advertised performance
Many SSDs are advertised with performance figures of 80,000 - 100,000 IOPS at some decent latency. Depending on the workload, you may only observe a fraction of that performance.
Most of those high 80K-100K IOPS figures are obtained by benchmarking with very high queue depths (16-32). The SSD benefits from such queue depths because it can handle a lot of those I/O requests in parallel.
Please beware: if your workload doesn't fit in that pattern, you may see lower performance numbers.
If we take a look at the chart above of the Intel SSD we may notice how the IOPS figures only start to come close to the advertised 80K+ IOPS as the queue depth increases. It's therefore important to understand the characteristics of your own workload.
RAID
If we group several hard drives together we can create a RAID array. A RAID array is a virtual storage device that exceeds the capacity and performance of a single hard drive. This allows storage to scale within the limits of a single computer.
RAID is also used (or some say primarily used) to assure availability by assuring redundancy (drive failure won't cause data loss). But for this article we focus it's performance characteristics.
SSDs can achieve impressive sequential throughput speeds, of multiple gigabytes per second. Individual hard drives can never come close to those speeds, but if you put a lot of them together in a RAID array, you can come very close. For instance, my own NAS an achieve such speeds using 24 drives.
RAID also improves the performance of random access patterns. The hard drives in a RAID array work in tandem to service those I/O requests so a RAID array shows significantly higher IOPS than a single drive. More drives means more IOPS.
RAID 5 with 8 x 7200 RPM drives
The picture below shows the read IOPS performance of an 8-drive RAID 5 array of 1 TB, 7200 RPM drives. We run a benchmark of random 4K read requests.
Notice how the IOPS increases as the queue depth increases.
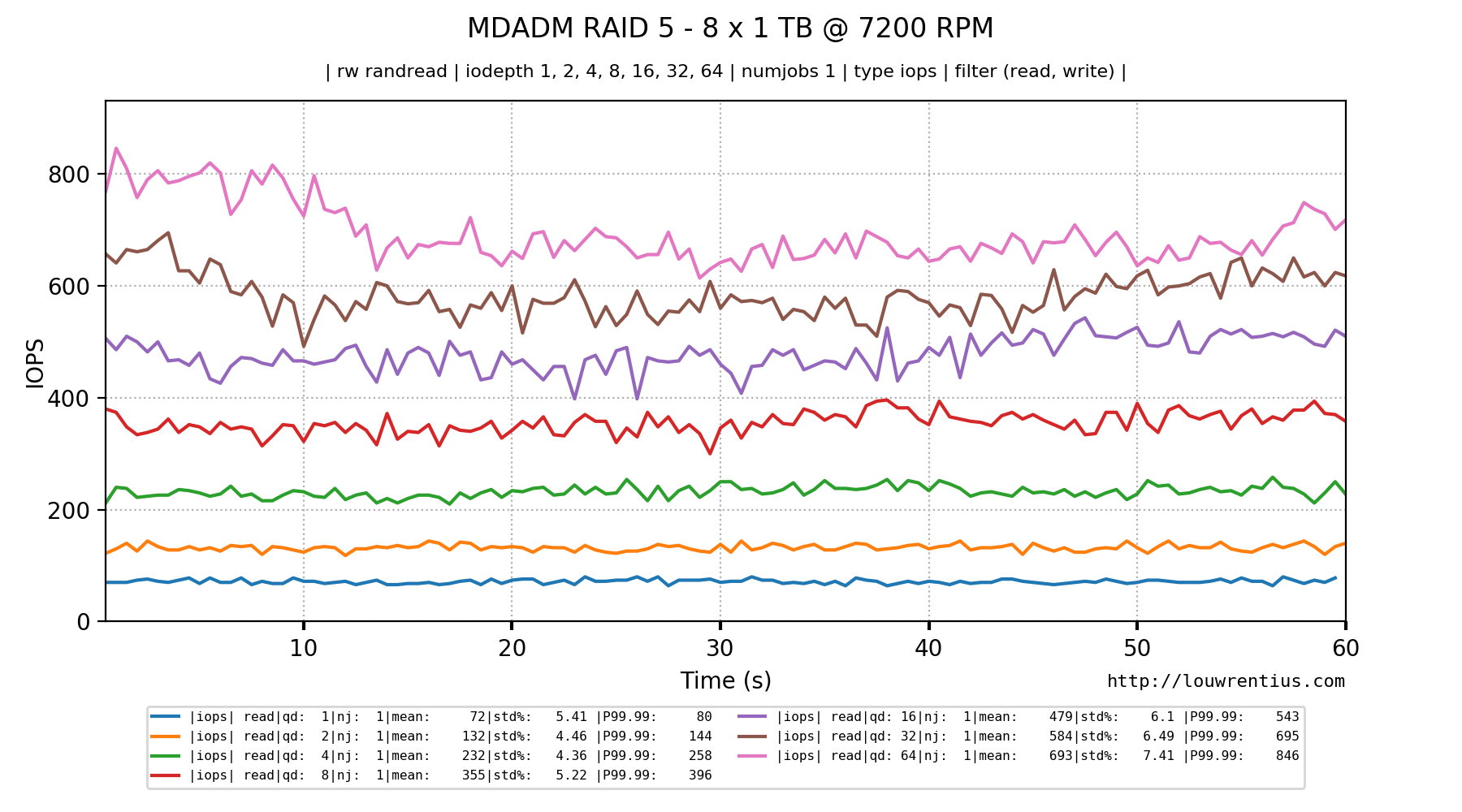
However, nothing is free in this world. A higher queue depth - which acts as a buffer - does increase latency.
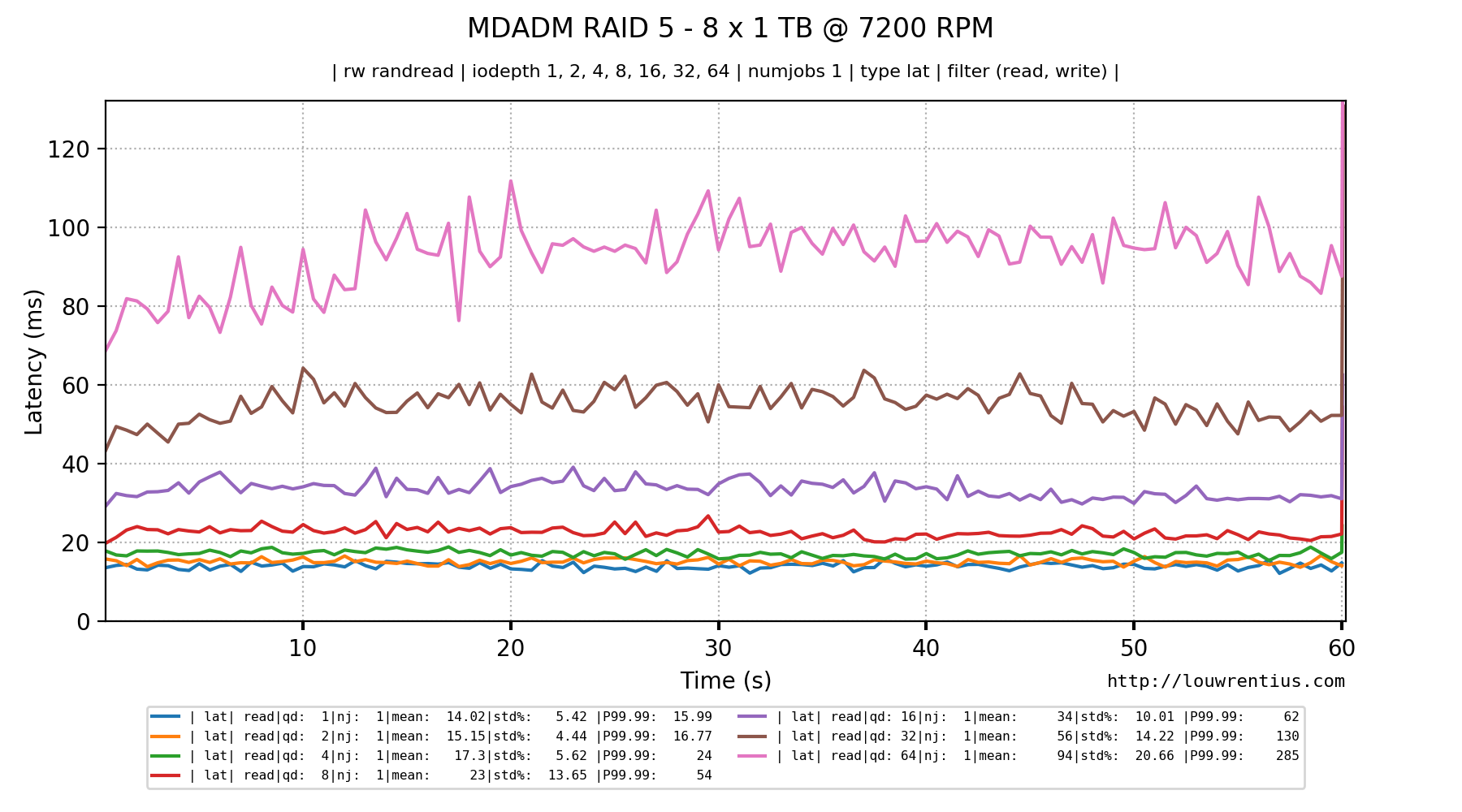
Notice how quickly the latency exceeds 20ms and quickly becomes almost unusable.
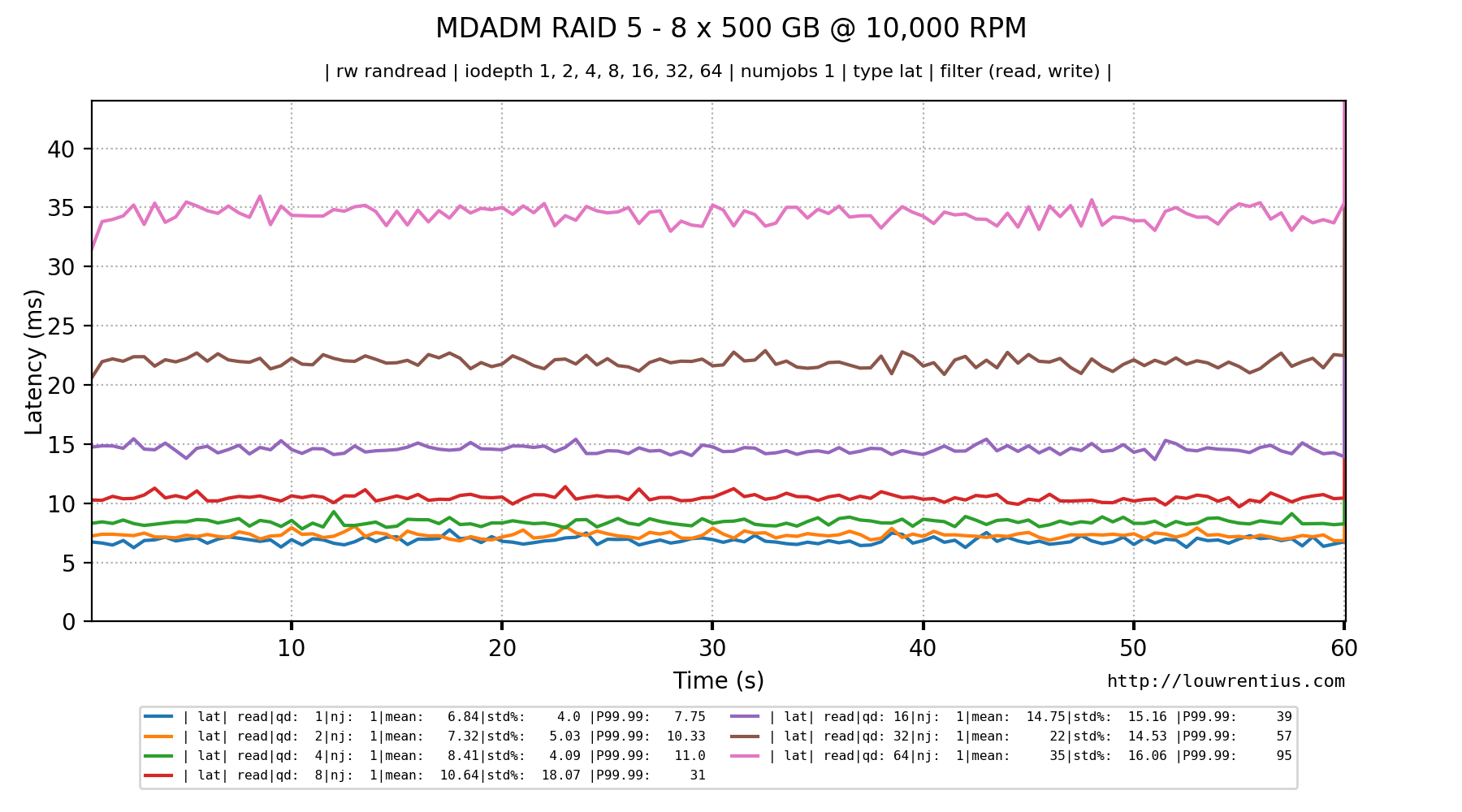
RAID 5 with 8 x 10,000 RPM drives
Below is the result of a similar test with 10,000 RPM hard drives. Notice how much better the IOPS and latency figures are.
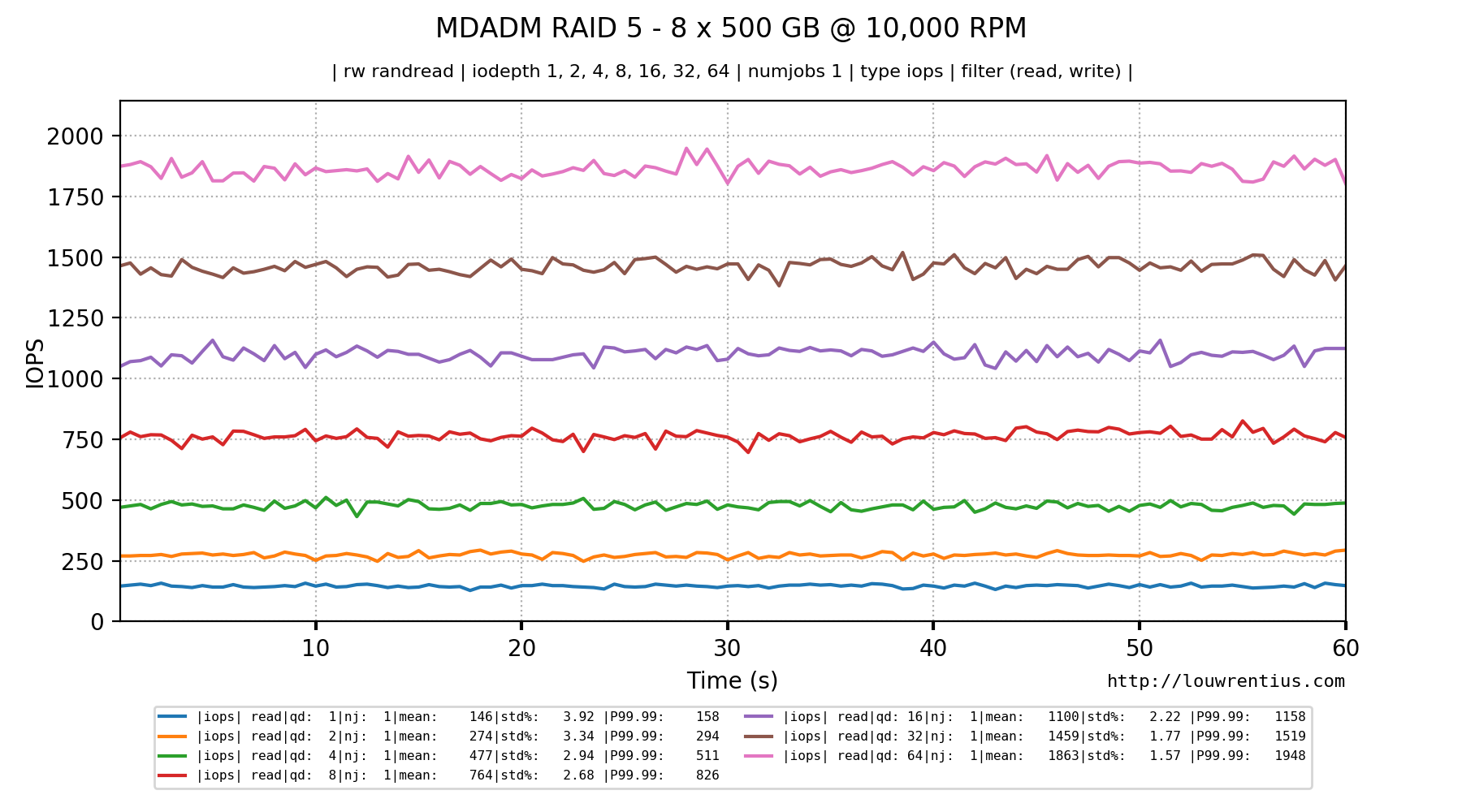
The latency looks much better:
It makes sense to put SSDs in RAID. Although they are more reliable than hard drives, they can fail. If you care about availability, RAID is inevitable. Furthermore, you can observe the same benefits as with hard drives: you pool resources together, achieving higher IOPS figures and more capacity than possible with a single SSD.
Capacity vs. Performance
The following is mostly focussed on hard drives although it could be true for solid state drives as well.
We put hard drives in RAID arrays to get more IOPS than a single drive can provide. At some point - as the workload increases - we may hit the maximum number of IOPS the RAID array can sustain with an acceptable latency.
This IOPS/Latency threshold could be reached even if we have only 50% of the storage capacity of our RAID array in use. If we use the RAID array to host virtual machines for instance, we cannot add more virtual machines because this would cause the latency to rise to unacceptable levels.
It may feel like a lot of good storage space is going to waste, and in some sense this may be true. For this reason, it could be a wise strategy to buy smaller 10,000 RPM or 15,000 RPM drives purely for the IOPS they can provide and forgo on capacity.
So it might be the case that you may have to order and add let's say 10 more hard drives to meet the IOPS/Latency demands while there's still plenty of space left.
This kind of situation is less likely as SSDs have taken over the role of the performance storage layer and (larger capacity) hard drives are pushed in the role of 'online' archival storage.
Closing words
I hope this article has given you a better understanding of storage performance. Although it is just an introduction, it may help you to better understand the challenges of storage performance.
-
https://en.wikipedia.org/wiki/Hard_disk_drive_performance_characteristics#Data_transfer_rate ↩

{kind=link}
Comments