Introduction
In this blog post I will try to explain why I believe Ceph is such an interesting storage solution. After you finished reading this blog post you should have a good high-level overview of Ceph.
I've written this blog post purely because I'm a storage enthusiast and I find Ceph interesting technology.
What is Ceph?
Ceph is a software-defined storage solution that can scale both in performance and capacity. Ceph is used to build multi-petabyte storage clusters.
For example, Cern has build a 65 Petabyte Ceph storage cluster. I hope that number grabs your attention. I think it's amazing.
The basic building block of a Ceph storage cluster is the storage node. These storage nodes are just commodity (COTS) servers containing a lot of hard drives and/or flash storage.

Example of a storage node
Ceph is meant to scale. And you scale by adding additional storage nodes. You will need multiple servers to satisfy your capacity, performance and resiliency requirements. And as you expand the cluster with extra storage nodes, capacity, performance and resiliency (if needed) will all increase at the same time.
It's that simple.
You don't need to start with petabytes of storage. You can actually start very small, with just a few storage nodes and expand as your needs increase.
I want to touch upon a technical detail because it illustrates the mindset surrounding Ceph. With Ceph, you don't even need a RAID controller anymore, a 'dumb' HBA is sufficient. This is possible because Ceph manages redundancy in software. A Ceph storage node at it's core is more like a JBOD. The hardware is simple and 'dumb', the intelligence resides all in software.
This means that the risk of hardware vendor lock-in is quite mitigated. You are not tied to any particular proprietary hardware.
What makes Ceph special?
At the heart of the Ceph storage cluster is the CRUSH algoritm, developed by Sage Weil, the co-creator of Ceph.
The CRUSH algoritm allows storage clients to calculate which storage node needs to be contacted for retrieving or storing data. The storage client can - on it's own - determine what to do with data or where to get it.
So to reiterate: given a particular state of the storage cluster, the client can calculate which storage node to contact for storage or retrieval of data.
Why is this so special?
Because there is no centralised 'registry' that keeps track of the location of data on the cluster (metadata). Such a centralised registry can become:
- a performance bottleneck, preventing further expansion
- a single-point-of-failure
Ceph does away with this concept of a centralised registry for data storage and retrieval. This is why Ceph can scale in capacity and performance while assuring availability.
At the core of the CRUSH algoritm is the CRUSH map. That map contains information about the storage nodes in the cluster. That map is the basis for the calculations the storage client need to perform in order to decide which storage node to contact.
This CRUSH map is distributed across the cluster from a special server: the 'monitor' node. Regardless of the size of the Ceph storage cluster, you typically need just three (3) monitor nodes for the whole cluster. Those nodes are contacted by both the storage nodes and the storage clients.
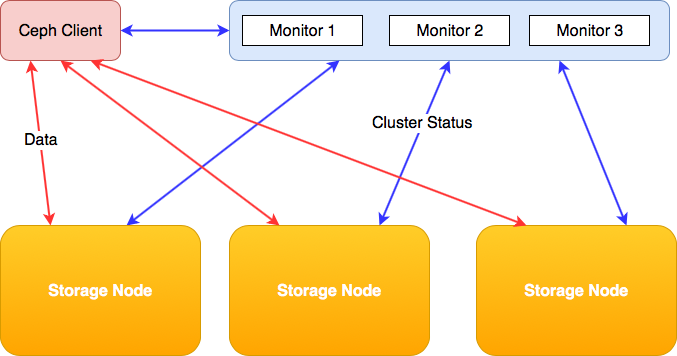
So Ceph does have some kind of centralised 'registry' but it serves a totally different purpose. It only keeps track of the state of the cluster, a task that is way easier to scale than running a 'registry' for data storage/retrieval itself.
It's important to keep in mind that the Ceph monitor node does not store or process any metadata. It only keeps track of the CRUSH map for both clients and individual storage nodes. Data always flows directly from the storage node towards the client and vice versa.
Ceph Scalability
A storage client will contact the appropriate storage node directly to store or retrieve data. There are no components in between, except for the network, which you will need to size accordingly1.
Because there are no intermediate components or proxies that could potentially create a bottleneck, a Ceph cluster can really scale horizontally in both capacity and performance.
And while scaling storage and performance, data is protected by redundancy.
Ceph redundancy
Replication
In a nutshell, Ceph does 'network' RAID-1 (replication) or 'network' RAID-5/6 (erasure encoding). What do I mean by this? Imagine a RAID array but now also imagine that instead of the array consisting of hard drives, it consist of entire servers.
That's what Ceph does: it distributes the data across multiple storage nodes and assures that the copy of a piece of data is never stored on the same storage node.
This is what happens if a client writes two blocks of data:
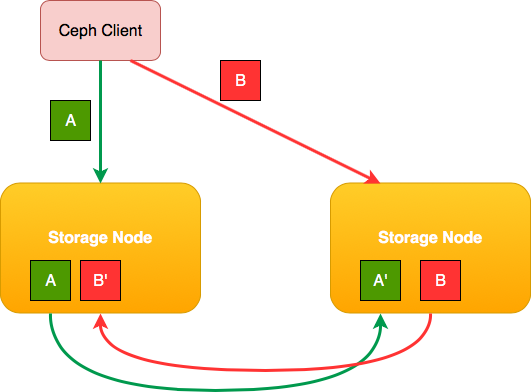
Notice how a copy of the data block is always replicated to other hardware.
Ceph goes beyond the capabilities of regular RAID. You can configure more than one replica. You are not confined to RAID-1 with just one backup copy of your data2. The only downside of storing more replicas is the storage cost.
You may decide that data availability is so important that you may have to sacrifice space and absorb the cost. Because at scale, a simple RAID-1 replication scheme may not sufficiently cover the risk and impact of hardware failure anymore. What if two storage nodes in the cluster die?
This example or consideration has nothing to do with Ceph, it's a reality you face when you operate at scale.
RAID-1 or the Ceph equivalent 'replication' offers the best overall performance but as with 'regular' RAID-1, it is not very storage space efficient. Especially if you need more than one replica of the data to achieve the level of redundancy you need.
This is why we used RAID-5 and RAID-6 in the past as an alternative to RAID-1 or RAID-10. Parity RAID assures redundancy but with much less storage overhead at the cost of storage performance (mostly write performance). Ceph uses 'erasure encoding' to achieve a similar result.
Erasure Encoding
With Ceph you are not confined to the limits of RAID-5/RAID-6 with just one or two 'redundant disks' (in Ceph's case storage nodes). Ceph allows you to use Erasure Encoding, a technique that let's you tell Ceph this:
"I want you to chop up my data in 8 data segments and 4 parity segments"

These segments are then scattered across the storage nodes and this allows you to lose up to four entire hosts before you hit trouble. You will have only 33% storage overhead for redundancy instead of 50% (or even more) you may face using replication, depending on how many copies you want.
This example does assume that you have at least 8 + 4 = 12 storage nodes. But any scheme will do, you could do 6 data segments + 2 parity segments (similar to RAID-6) with only 8 hosts. I think you catch the idea.
Ceph failure domains
Ceph is datacenter-aware. What do I mean by that? Well, the CRUSH map can represent your physical datacenter topology, consisting of racks, rows, rooms, floors, datacenters and so on. You can fully customise your topology.
This allows you to create very clear data storage policies that Ceph will use to assure the cluster can tollerate failures across certain boundaries.
An example of a topology:
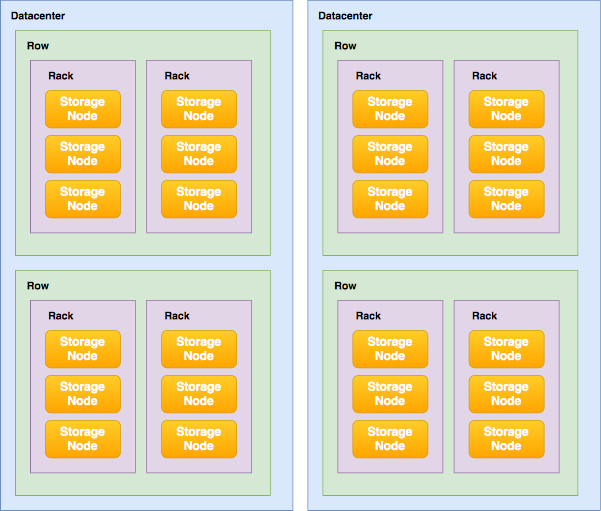
If you want, you can lose a whole rack. Or a whole row of racks and the cluster could still be fully operational, although with reduced performance and capacity.
That much redundancy may cost so much storage that you may not want to employ it for all of your data. That's no problem. You can create multiple storage pools that each have their own protection level and thus cost.
How do you use Ceph?
Ceph at it's core is an object storage solution. Librados is the library you can include within your software project to access Ceph storage natively. There are Librados implementations for the following programming languages:
- C(++)
- Java
- Python
- PHP
Many people are looking for more traditional storage solutions, like block storage for storing virtual machines, a POSIX compliant shared file system or S3/OpenStack Swift compatible object storage.
Ceph provides all those features in addition to it's native object storage format.
I myself are mostly interested in block storage (Rados Block Device)(RBD) with the purpose of storing virtual machines. As Linux has native support for RBD, it makes total sense to use Ceph as a storage backend for OpenStack or plain KVM.
With very recent versions of Ceph, native support for iSCSI has been added to expose block storage to non-native clients like VMware or Windows. For the record, I have no personal experience with this feature (yet).
The Object Storage Daemon (OSD)
In this section we zoom in a little bit more into the technical details of Ceph.
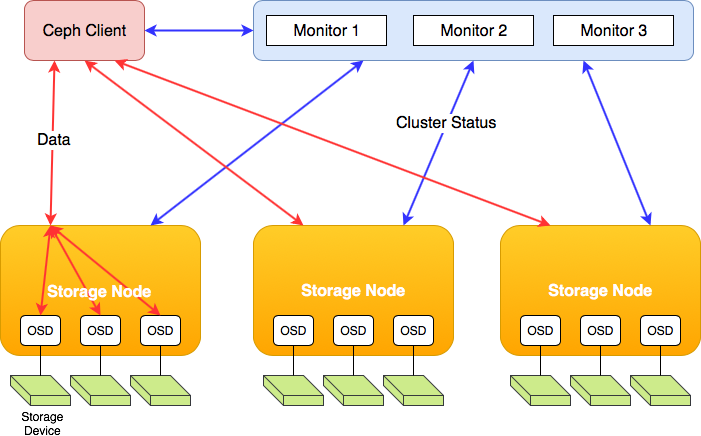
If you read about Ceph, you read a lot about the OSD or object storage daemon. This is a service (daemon) that runs on the storage node. The OSD is the actual workhorse of Ceph, it serves the data from the hard drive or ingests it and stores it on the drive. The OSD also assures storage redunancy, by replicating data to other OSDs based on the CRUSH map.
To be precise: for every hard drive or solid state drive in the storage node, an OSD will be active. Does your storage node have 24 hard drives? Then it runs 24 OSDs.
And when a drive goes down, the OSD will go down too and the monitor nodes will redistribute an update CRUSH map so the clients are aware and know where to get the data. The OSDs also respond to this update, because redundancy is lost, they may start to replicate non-redundant data to make it redundant again (across fewer nodes).
When the drive is replaced, the cluster will 'self-heal'. This means that the new drive will be filled with data once again to make sure data is spread evenly across all drives within the cluster.
So maybe it's interesting to realise that storage clients effectively directly talk to the OSDs that in turn talk to the individual hard drives. There aren't many components between the client and the data itself.
Closing words
I hope that this blog post has helped you understand how Ceph works and why it is so interesting. If you have any questions or feedback please feel free to comment or email me.
-
If you have a ton of high-volume sequential data storage traffic, you should realise that a single host with a ton of drives can easily saturate 10Gbit or theoretically even 40Gbit. I'm assuming 150 MB/s per hard drive. With 36 hard drives you would face 5.4 GB/s. Even if you only would run half that speed, you would need to bond multiple 10Gbit interfaces to sustain this load. Imagine the requirements for your core network. But it really depends on your workload. You will never reach this kind of throughput with a ton of random I/O unless you are using SSDs, for instance. ↩
-
Please note that in production setups, it's the default to have a total of 3 instances of a data block. So that means 'the original' plus two extra copies. See also this link. Thanks to sep76 from Reddit to point out that the default is 3 instances of your data. ↩


Comments