The price of Solid-state drives (SSDs) has dropped significantly over the last few years. It's now possible to buy a 1TB solid-state drive for less than €60. However, at such low price points, there is a catch.
Although cheap SSDs do perform fine regarding reads, sustained write performance can be really atrocious. To demonstrate this concept, I bought a bunch of the cheapest SATA SSDs I could find - as listed below - and benchmarked them with Fio.
| Model | Capacity | Price |
|---|---|---|
| ADATA Ultimate SU650 | 240 GB | € 15,99 |
| PNY CS900 | 120 GB | € 14,56 |
| Kingston A400 | 120 GB | € 20,85 |
| Verbatim Vi550 S3 | 128 GB | € 14,99 |
I didn't have the budget to buy a bunch of 1TB of 2TB SSD, so these ultra-cheap, low capacity SSDs are a bit of a stand-in. I've also added a Crucial MX500 1TB (CT1000MX500SSD1) SATA1 SSD - which I already owned - to the benchmarks to see how well those small-capacity SSDs stack up to a cheap SSD with a much larger capacity.
Understanding SSD write performance
To understand the benchmark results a bit better, we discuss some SSD concepts in this section. Feel free to skip to the actual benchmarks if you're already familiar with them.
SLC Cache
SSDs originally used single-level cell (SLC) flash memory, which can hold a single bit and is the fastest and most reliable flash memory available. Unfortunately, it's also the most expensive. To reduce cost, multi-level cell (MLC) flash was invented, which can hold two bits instead of one, at the cost of speed and longevity2. This is even more so for triple-level cell (TLC) and quad-level cell (QLC) flash memory. All 'cheap' SSDs I benchmark use 3D v-nand3 TLC flash memory.
One technique to temporarily boost SSD performance is to use a (small) portion of (in our case) TLC flash memory as if it was SLC memory. This SLC memory then acts as a fast write cache4. When the SSD is idle, data is moved from the SLC cache to the TLC flash memory in the background. However, this process is limited by the speed of the 'slower' TLC flash memory and can take a while to complete.
While this trick with SLC memory works well for brief, intermittent write loads, sustained write loads will fill up the SLC cache and cause a significant drop in performance as the SSD is forced to write data into slower TLC memory.
DRAM cache
As flash memory has a limited lifespan and can only take a limited number of writes, a wear-leveling mechanism is used to distribute writes over all cells evenly, regardless of where data is written logically. Keeping track of this mapping between logical and physical 'locations' can be sped up with a DRAM cache (chip) as DRAM tend to be faster than flash memory. In addition, the DRAM can also be used to cache writes, improving performance. Cheap SSDs don't use DRAM cache chips to reduce cost, thus they have to update their data mapping tables in flash memory, which is slower. This can also impact (sustained) write performance. To be frank, I'm not sure how much a lack of DRAM impacts our benchmarks.
Benchmark method
Before I started benchmarking I submitted a trim command to clear each drive. Next, I performed a sequential write benchmark of the entire SSD with a block size of 1 megabyte and a queue depth of 32. The benchmark is performed on the 'raw' device, no filesystem is used. I used Fio for these benchmarks.
Benchmark results
The chart below shows write bandwith over time for all tested SSDs. Each drive has been benchmarked in full, but the data is truncated to the first 400 seconds for readability (performance didn't change). The raw Fio benchmark data can be found here (.tgz).
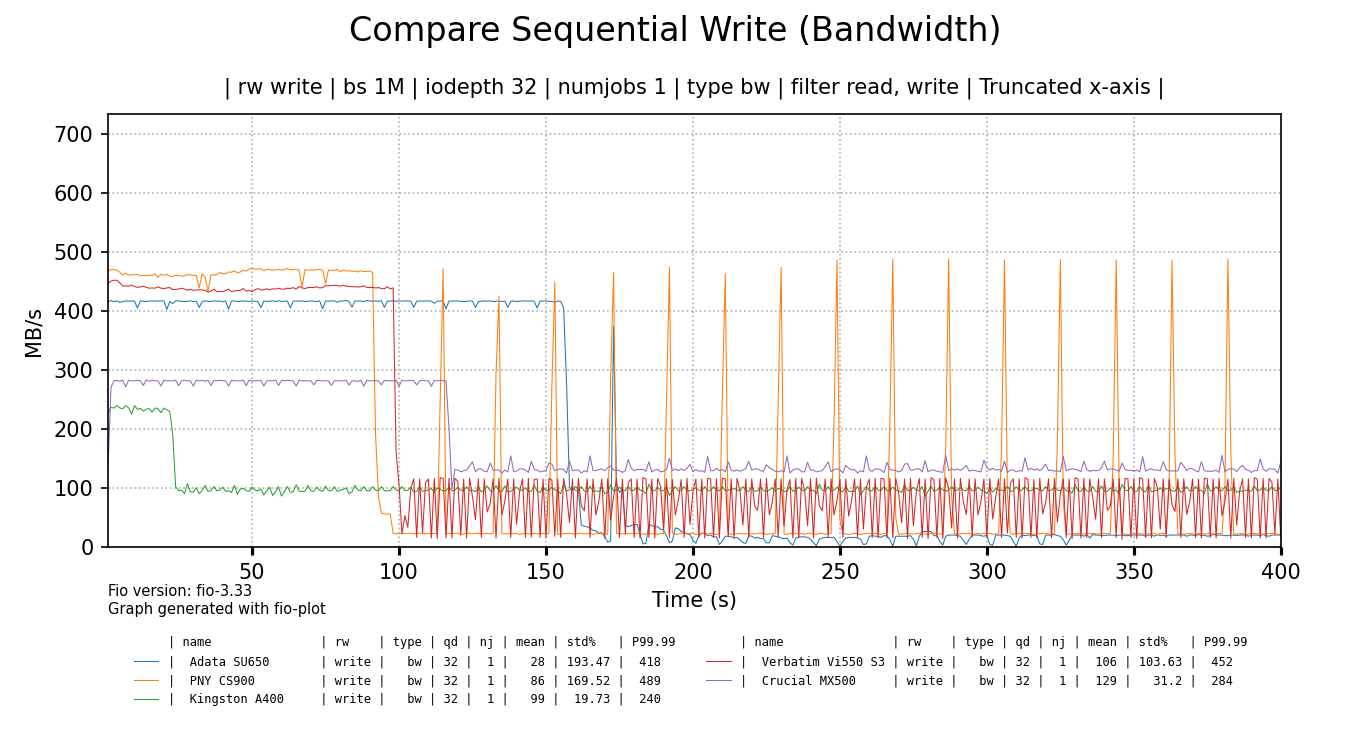
click for a larger image
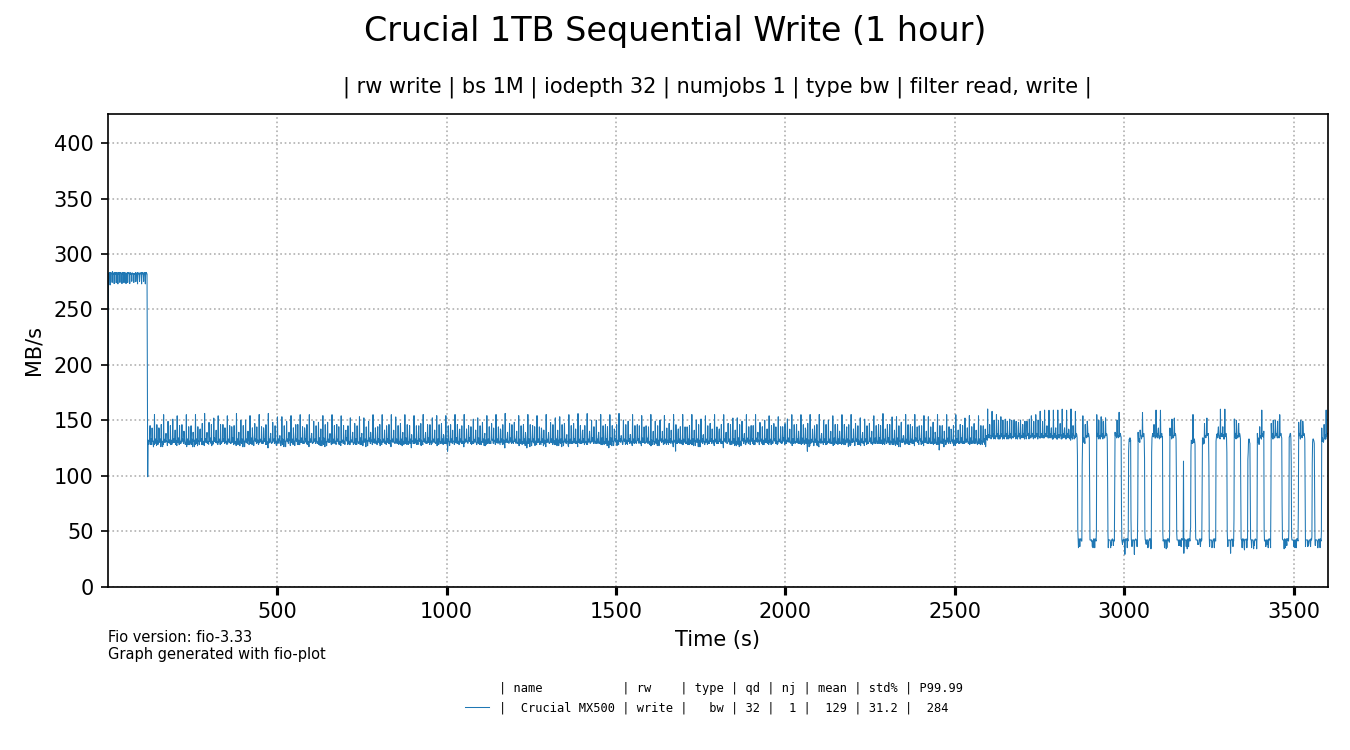
It's funny to me that some cheap SSDs initially perform way better than the more expensive Crucial 1TB SSD5. As soon as their SLC cache runs out, the Crucial 1TB has the last laugh as it shows best sustained throughput, beating all cheaper drives, but the Kingston A400 comes close.
Of all the cheap SSDs only the Kingston shows the best sustained write speed at around 100 MB/s and there are no intermittent drops in performance. The ADATA, PNY and Verbatim SSDs show flakey behaviour and basically terrible sustained write performance. But make no mistake, I would not call the performance of the Kingston SSD, nor the Crucial SSD - added as a reference - 'good' by any definition of that word. Even the Kingston can't saturate gigabit Ethernet.
The bandwidth alone doesn't tell the whole story. The latency or responsiveness of the SSDs is also significantly impacted:
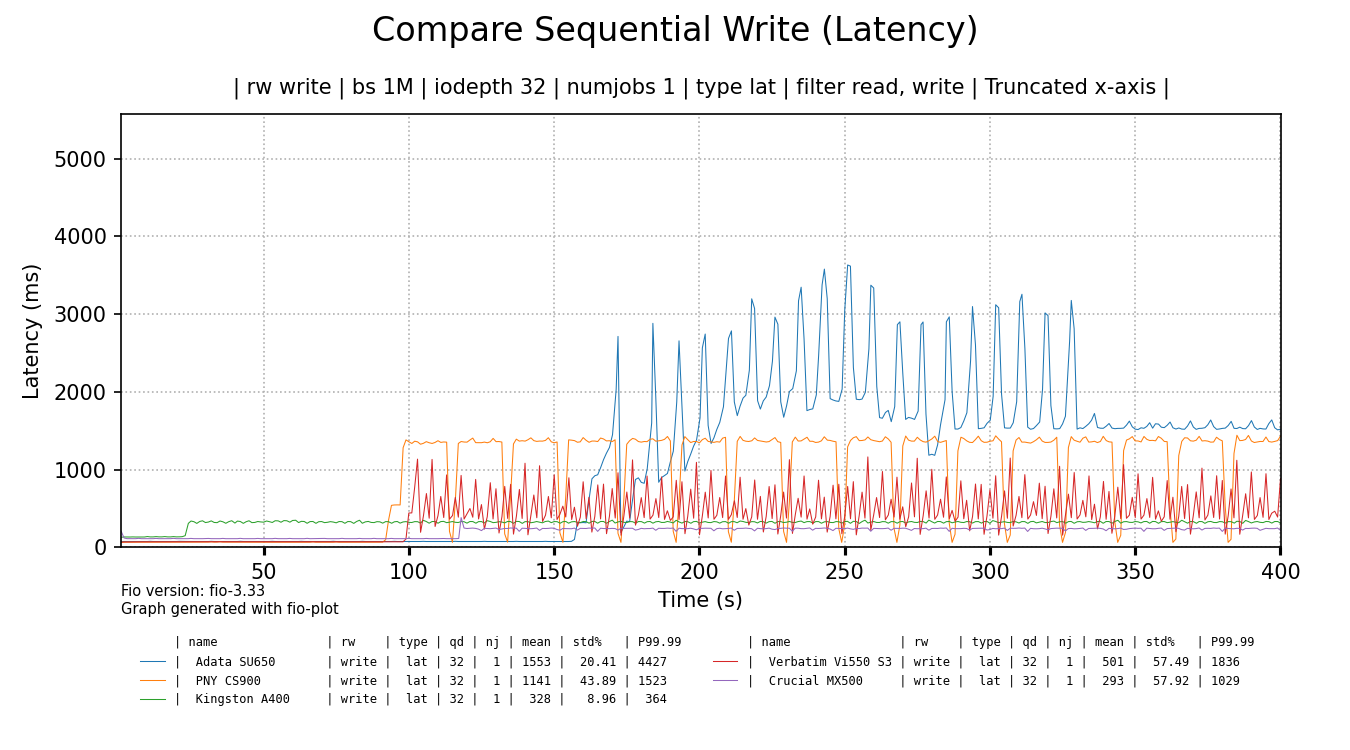
click for a larger image
The Crucial 1TB SSD shows best latency overall, followed by the Kingston SSD. The rest of the cheap SSDs show quite high latency spikes and very high latency overall, even when some of the spikes settle, like for the ADATA SSD. When latency is measured in seconds, things are bad.
To put things a bit in perspective, let's compare these results to a Toshiba 8 TB 7200 RPM hard drive I had lying around.
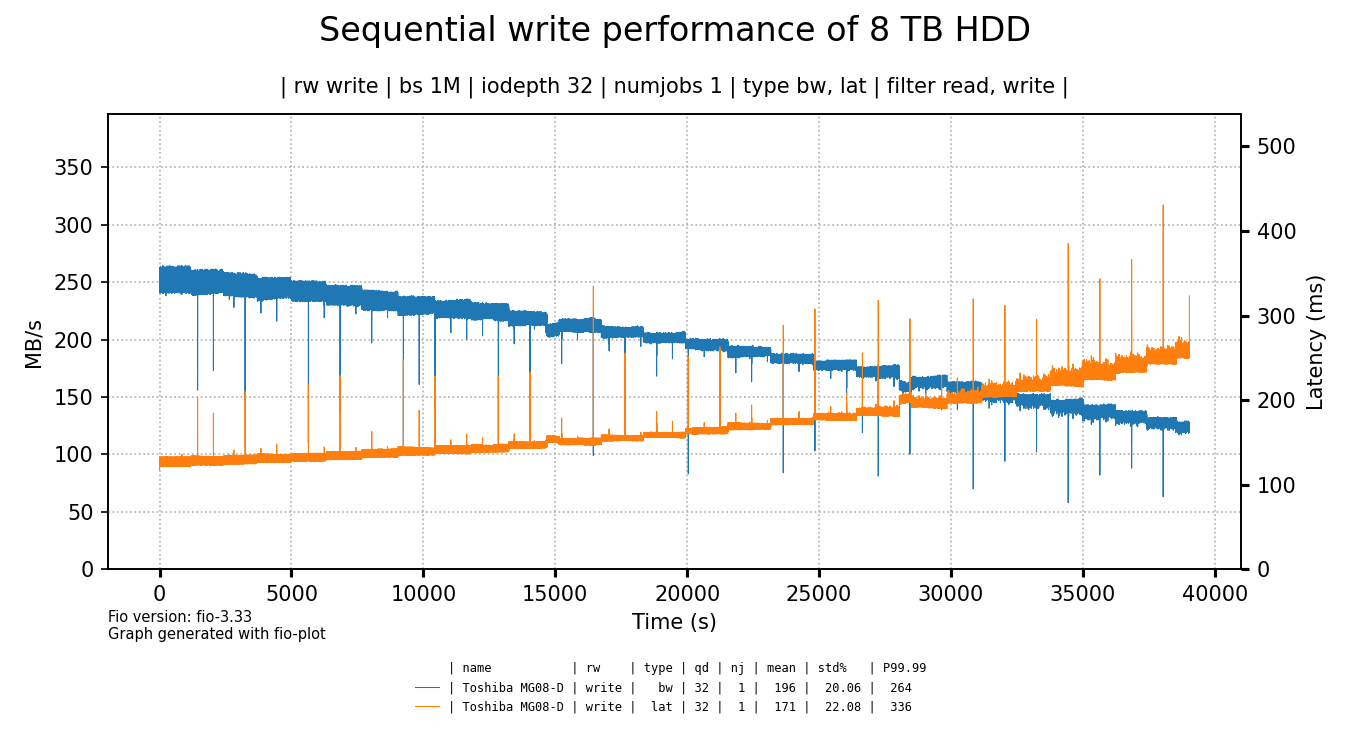
click for a larger image
The hard drive shows better write throughput and latency6 as compared to most of the tested SSDs. Yes, except for the initial few minutes where the cheap SSDs tend to be faster (except for the Kingston & Crucial SSDs) but how much does that matter?
As we've shown the performance of a hard drive to contrast the terrible write performance of the cheap SSDs, it's time to also compare them to a more expensive, higher-tier SSD.
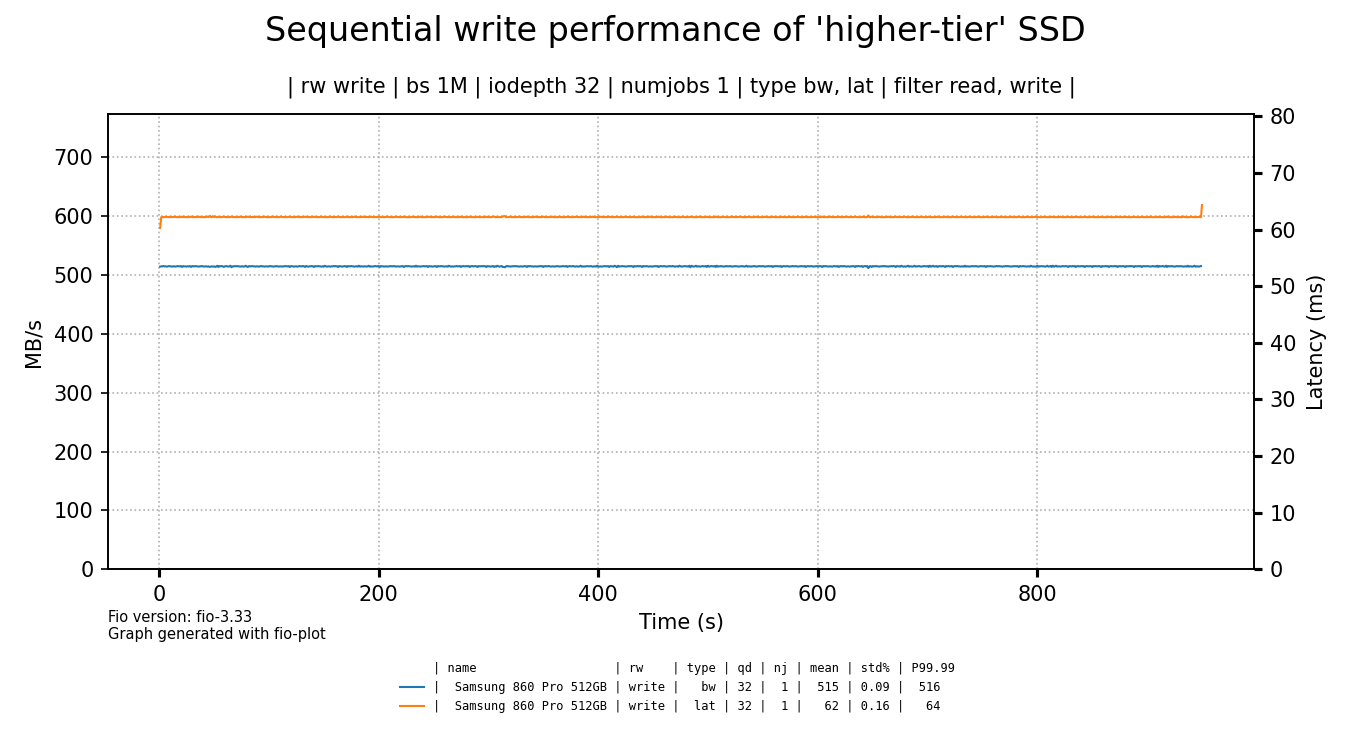
click for a larger image
I've bought this Samsung SSD in 2019 for €137 euro, so that's quite a different price point. I think the graph speaks for itself, especially if you consider that this graph is not truncated, this is the full drive write.
Evaluation & conclusion
One of the funnier conclusions to draw is that it's beter to use a hard drive than to use cheap SSDs if you need to ingest a lot of data. Even the Crucial 1TB SSD could not keep up with the HDD.
A more interesting conclusion is that the 1TB SSD didn't perform that much better than the small cheaper SSDs. Or to put it differently: although the performance of the small, cheap SSDs is not representative of the larger SSD, it is still quite in the same ball park. I don't think it's a coincidence that the Kingston SSD came very close to the performance of the Crucial SSD, as it's the most 'expensive' of the cheap drives.
In the end, my intend was to demonstrate with actual benchmarks how cheap SSDs show bad sustained write performance and I think I succeeded. I hope it helps people to understand that good SSD write performance is not a given, especially for cheaper drives.
The Hacker News discussion of this blog post can be found here
Disclaimer
I'm not sponsored in any way. All mentioned products have been bought with my own money.
The graphs are created with fio-plot, a tool I've made and maintain. The benchmarks have been performed with bench-fio, a tool included with fio-plot, to automate benchmarking with Fio.
-
As I don't have a test system with NVMe, I had to use SATA-based SSDs. The fact that the SATA interface was not the limiting factor in any of the tests, is foreboding. ↩
-
As a general note, I think the vast majority of users should not worry about SSD longevity in general. Only people with high-volume write workloads should keep an eye on write endurance of SSD and buy a suitable product. ↩
-
instead of packing the bits really dense together in a cell horizontally, the bits are stacked vertically, saving horizontal space. This allows for higher data densities in the same footprint. ↩
-
Some SSDs have a static SLC cache, but others size the SLC cache in accordance to how full an SSD is. When the SSD starts to fill up, the SLC cache size is reduced. ↩
-
After around 45-50 minutes of testing, performance of the Crucial MX 500 also started to drop to around 40 MB/s and fluctuate up and down. Evidence. ↩
-
it's so funny to me that a hard drive beats an SSD on latency. ↩






{kind=link}