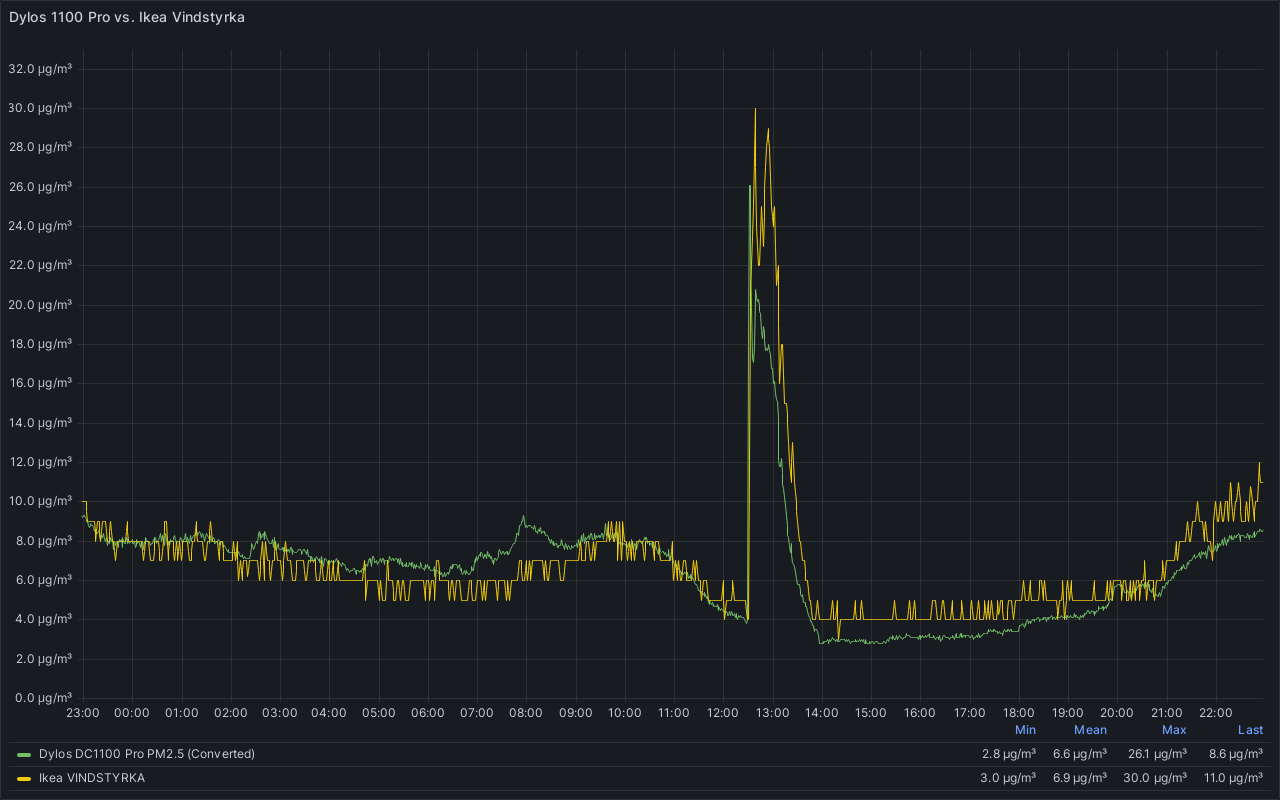
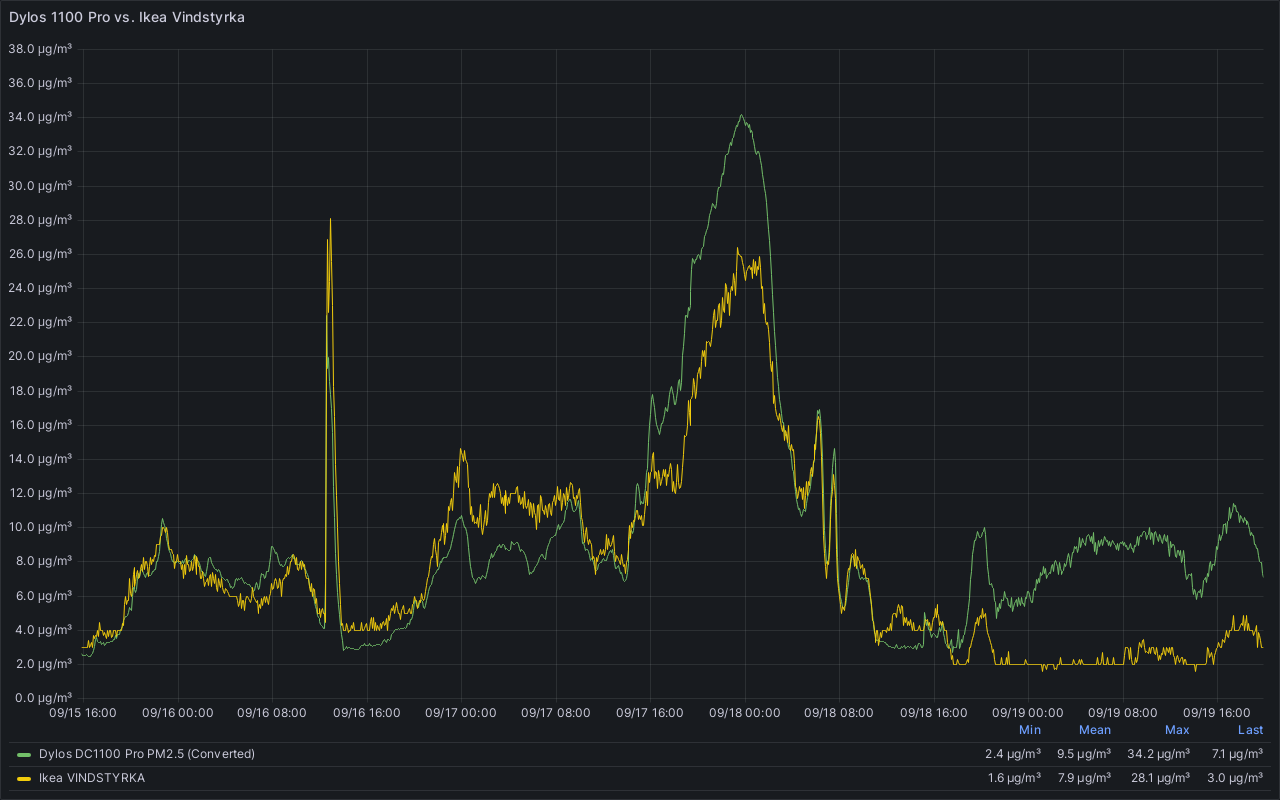
Introduction
Victron Multiplus-II inverter/charges are configured with the veconfigure1 tool. Unforntunately this is a Windows-only tool, but there is still a way for Apple users to run this tool without any problems.
Tip: if you've never worked with the Terminal app on MacOS, it might not be an easy process, but I've done my best to make it as simple as I can.
A tool called 'Wine' makes it possible to run Windows applications on MacOS. There are some caveats, but none of those apply to veconfigure, this tool runs great!
I won't cover in this tutorial how to make the MK-3 USB cable work. This tutorial is only meant for people who have a Cerbo GX or similar device, or run VenusOS, which can be used to remotely configure the Multipluss device(s).
Step 1: install brew on macos
Brew is a tool that can install additional software
- Visit https://brew.sh and copy the install command
- open the Terminal app on your mac and paste the command
- now press 'Enter' or return
It can take a few minutes for 'brew' to install.
Step 2: install wine
Enter the following two commands in the terminal:
brew tap homebrew/cask-versions
brew install --cask --no-quarantine wine-stable
Download Victron veconfigure
- Visit this page
- Scroll to the section "VE Configuration tools for VE.Bus Products"
- Click on the link "Ve Configuration Tools"
- You'll be asked if it's OK to download this file (VECSetup_B.exe) which is ok
Start the veconfigure installer with wine
- Open a terminal window
- Run
cd - Enter the command
wine Downloads\VECSetup_B.exe - Observe that the veconfigure Windows setup installer starts
- Click on next, next, install and Finish
- veconfigure will run for the first time
Click on the top left button on the video to enlarge
These are the actual install steps:
How to start veconfigure after you close the app
- Open a terminal window
- Run
cd - Run
cd .wine/drive_c/Program\ Files\ \(x86\)/VE\ Configure\ tools/ - Run
wine VEConfig.exe
Observe that veconfigure starts
Allow veconfigure access to files in your Mac Download folder
- Open a terminal window
- Run
cd - run
cd .wine/drive_c/ - run
ls -n ~/Downloads
We just made the Downloads directory on your Mac accessible for the vedirect software. If you put the .RSVC files in the Downloads folder, you can edit them.
Please follow the instructions for remote configuration of the Multiplus II.
-
Click on the "Ve Configuration Tools" link in the "VE Configuration tools for VE.Bus Products" section. ↩