Introduction
Update December 2023:
In June, it was announced that iXsystems would sponsor implementing the VDEV expansion feature. A new pr has been created for this effort. The feature was merged into the code base, but may not be available to the general public before the end of 2024.
Many home NAS builders consider using ZFS for their file system. But there is a caveat with ZFS that people should be aware of.
Although ZFS is free software, implementing ZFS is not free. The key issue is that expanding capacity with ZFS is more expensive compared to legacy RAID solutions.
With ZFS, you either have to buy all storage you expect to need upfront, or you will be wasting a few hard drives on redundancy you don't need.
This fact is often overlooked, but it's very important to take it in consideration when planning a NAS build.
Other software RAID solutions like Linux MDADM lets you grow an existing RAID array with one disk at a time. This is also true for many hardware-based RAID solutions. This is ideal for home users because you can expand on a per-need basis.
ZFS does not allow this!
To understand why using ZFS may cost you extra money, we will dig a little bit into ZFS itself.
Quick recap of ZFS
The schema below illustrates the architecture of ZFS. There are a few things you should take away from it.
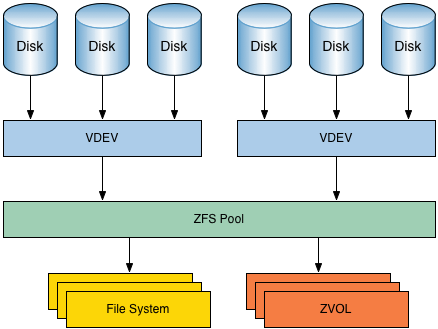
The main takeaway of this picture is that your ZFS pool and thus your file system is based on one or more VDEVs. And those VDEVs contain the actual hard drives.
Fault-tolerance or redundancy is addressed within a VDEV. A VDEV is either a mirror (RAID-1), RAIDZ (RAID-5) or RAIDZ2 (RAID-6).
So it's important to understand that a ZFS pool itself is not fault-tolerant. If you lose a single VDEV within a pool, you lose the whole pool. You lose the pool, all data is lost.
You can't add hard drives to a VDEV
Now it's very important to understand that you cannot add hard drives to a VDEV.
This is the key limitation of ZFS as seen from the perspective of home NAS builders.
To expand the storage capacity of your pool, you need to add extra VDEVs. And because each VDEV needs to take care of its own redundancy, you also need to buy extra drives for parity.
I will quickly add that there is a way out: replace every hard drive in the VDEV, one by one, with a higher capacity hard drive. You will have to 'rebuild' or 'resilver' the VDEV after each replacement, but it will work, although it's a bit cumbersome and quite expensive.
So back to the topic at hand: what does this limitation mean in real life? I'll give an example.
Let's say you plan on building a small NAS with a capacity of four drives. Please don't create a three-drive RAID-Z thinking you can just add the fourth drive when you need to, because that's not possible.
In this example, you would be better off buying the fourth drive upfront and create a four-drive RAID-Z. This is an example where you are forced to buy the extra space you don't need yet upfront because expanding is otherwise not possible.
You could have expanded your pool with another VDEV consisting of a minimum of three drives (if you run RAID-Z) but the chassis has only room for one extra drive so that doesn't work.
Planning your ZFS Build with the VDEV limitation in mind
Many home NAS builders use RAID-6 (RAID-Z2) for their builds, because of the extra redundancy. This makes sense because a double drive failure is not something unheard of, especially during rebuilds where all drives are being taxed quite heavily for many hours.
I personally would recommend running RAID-Z2 over RAID-Z1 if you go over five to six drives and to spend the extra money on the additional hard drive it requires. Actually, With RAID-Z2 or RAID-6, I think it's perfectly reasonable to run a single VDEV at home with up to 12 drives.
With RAID-Z2 however, the 'ZFS tax' is even more clearly visible. By having to add an additional VDEV, you will also lose two drives due to parity overhead.
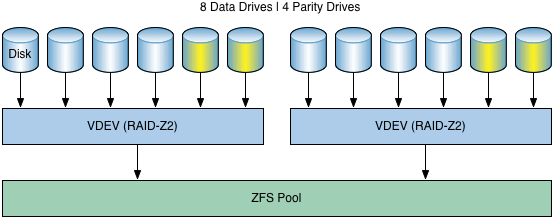
Please note that the 'yellow' drives mark the parity/redundancy overhead. It does not mark where parity data lives (it's striped across all drives).
Let's illustrate the above picture with an example. Your NAS chassis can hold a maximum of twelve drives. You start out with six drives in a RAID-Z2. At some point you want to expand. The cheapest option is to expand with another RAID-Z2 consisting of four drives (minimum size of a RAID-Z2 VDEV).
With a cost of $150 per hard drive, expanding the capacity of your pool will cost you $600 instead of $150 (single drive) and $300 dollar of the $600 (50%) is wasted on redundancy you don't really need.
Furthermore, you can no longer expand your pool, so the remaining two drive slots are 'wasted'. You end up with a maximum of ten drives.
In this example, to make use of the drive capacity of your NAS chassis, you should expand with another six hard drives. That would cost you $900 and $300 of that $900 (33%) is wasted on redundancy. This is illustrated above.
Storage-wise it's more efficient to expand with six drives instead of four. But it will cost you another $300 to expand, paying for storage you may not immediately need.
But both options aren't that efficient. Because you end up using four drives for parity where two would - in my view - be sufficient.
So, if you want to get the most capacity out of that chassis, and the most space per dollar, your only option is to buy all twelve drives upfront and create a single RAID-Z2 consisting of twelve drives.
Buying all drives upfront is expensive and you may only benefit from that extra space years down the road.
Summary
So I hope this example clearly illustrates the issue at hand. With ZFS, you either need to buy all storage upfront or you will lose hard drives to redundancy you don't need, reducing the maximum storage capacity of your NAS.
You have to decide what your needs are. ZFS is an awesome file system that offers you way better data integrity protection than other file system + RAID solution combination.
But implementing ZFS has a certain 'cost'. You must decide if ZFS is worth it for you.
Update April 2023:
It has been fairly quiet since the announcement of RAIDZ expansion.
The Github PR about this feature is rather stale and people are wondering what the status is and what the plans are. Meanwhile, FreeBSD has announced In February 2023 that they suspect to integrate RAIDZ expansion by Q3.
Update June 2021|
It seems that RAIDZ expansion is now being worked on. It will probably be available somewhere around August 2022.
I have written a blogpost about this new feature. The bad news is that adding drives to an existing vdev may accrue some overhead, but the good news is that this overhead can be recovered.
Update October 2017 |
Please note that RAIDZ expansion is under development.
Addressing some feedback
I found out that my article was discussed on a vodcast of BSDNOW.
This article also got some attention on hacker news.
To me, some of the feedback is not 'wrong' but feels rather disingenuous or not relevant for the intended audience of this article. I have provided the links so you can make up your own mind.
This article has a particular user group in mind so you really should think about how much their needs align with yours.
You are steering people away from ZFS
No I don't and this is not my intention. I run ZFS myself on two servers. I do feel that sometimes the downsides of ZFS are wiped under the rug and we should be very open and clear about them towards people seeking advice.
Use mirrors not RAID-Z(2/3)!
Doesn't make much sense to me for home NAS builders.
Using mirrors is wasting space
Advising people to use mirrors instead of RAID-Z(2/3) I do find a little bit disingenuous. Because you are throwing away 50% of your disk capacity. With RAIDZ you 'lose' 33% for three drives, 25% for four drives. If we look at RAIDZ2, we would 'lose' 33% for six drives, 25% for eight drives and only 20% for ten drives.
In the end, you are waisting multiple drives worth of storage capacity depending on the number of drives in your pool.
Adding mirrors with larger drives
As time goes by, larger disks become cheaper. So it could make sense to expand your pool with mirrors based on bigger drives than the original drives you started out on. The size of your pool would increase. However, it's still only 50% space efficient.
Random I/O performance is better
Using mirrors is running RAID 10. Yes you can expand your pool with two drives at a time, and you gain better random I/O performance. However, the large majority of home NAS builders don't care about random I/O performance. You just care if you can saturate gigabit and have one big pool of storage. In that case, you don't need the random IOPs.
If you run some VMs from your storage that require high storage performance, it's an entirely different matter. But I expect that most DIY NAS builders just want some storage to put a ton of data on and nothing more.
RAIDZ2 is more reliable than using mirrors
The redundancy of RAIDZ2 beats using mirrors. (If during a rebuild the surviving member of a mirror fails (the one disk in the pool that is taxed the most during rebuild) you lose your pool. With RAIDZ2 any second drive can fail and you are still OK.
There is only one 'upside' regarding mirrors that is discussed in the next section.
Mirror rebuild times are better
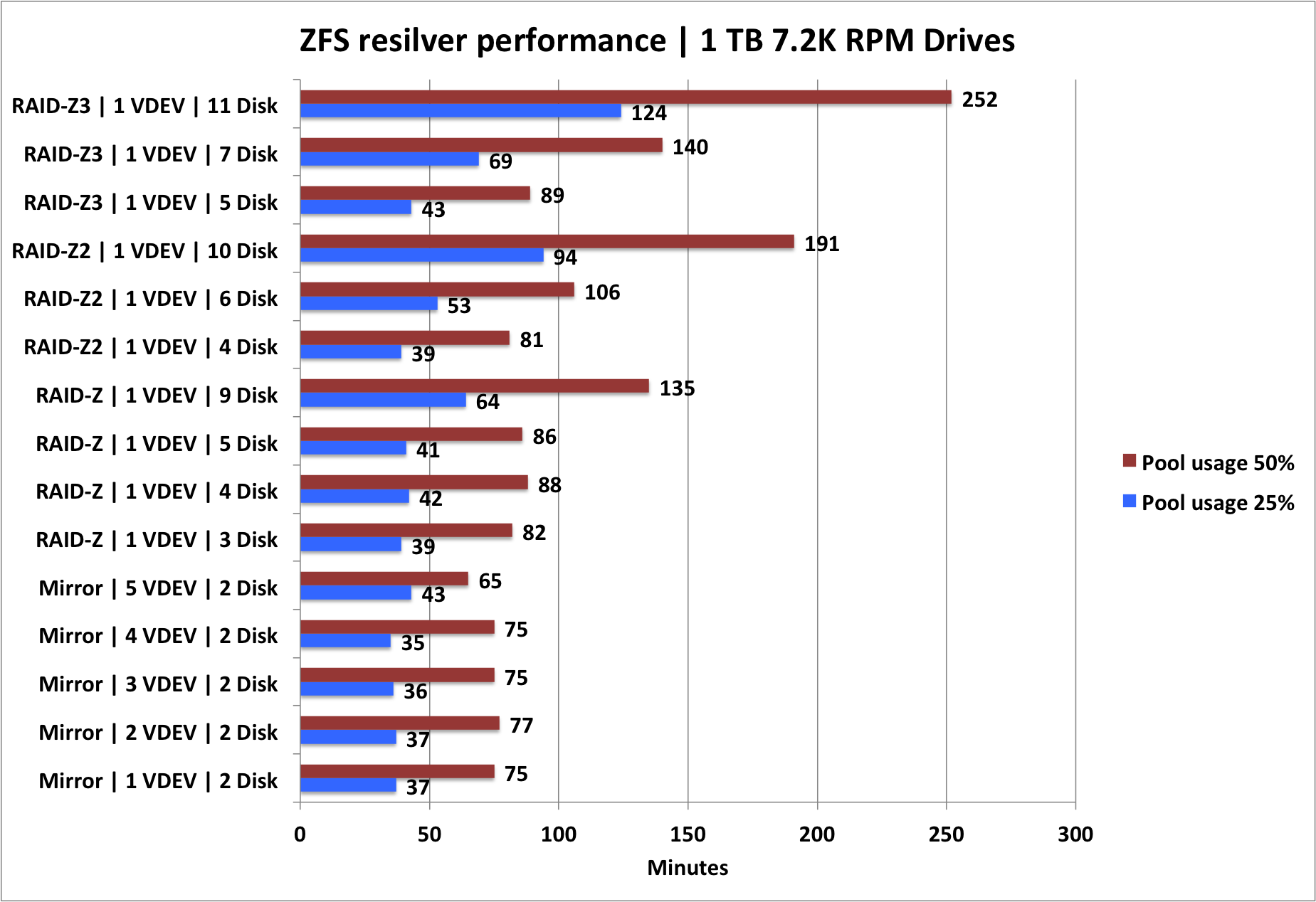
The only upside of using mirrors is that in the event a disk has failed and the new disk is being 'resilvered' it is reported that those rebuilds tend to be faster than if you use RAID-Z(2/3). I think this is no different from legacy RAID, where the main difference with ZFS is that ZFS only rebuilds actual data, not the entire disk.
ZFS rebuilds are faster
This is indeed a benefit of ZFS. The question is how relevant it is for you.
ZFS only rebuilds data. Legacy RAID just rebuilds every 'bit' on a drive. The latter takes longer than the former. So with legacy RAID, rebuild times depend on the size of a single drive, not on the number of drives in the array, no matter how much data you have stored on your array.
My old 18 TB server was based on a single twenty-drive RAID 6 using MDADM. It took 5 hours to rebuild a 1 TB drive. If you would have used 4 TB drives, it would have taken 20 hours if I'm allowed to extrapolate. With ZFS - if you would have been using only 50% of capacity - those rebuild times would have been half of this.
Personally with RAID6 or with RAIDZ2, rebuild times aren't that a big of a deal as you can lose a second drive and still be safe.
Just replace existing drives with bigger ones!
I did briefly touch this option in the article above. I will address it again. The problem with this approach is twofold. First, you can't expand storage capacity as you need it. You need to replace all existing drives with larger ones.
The procedure itself is also a bit cumbersome and time intensive. You need to replace each drive one by one. And every time, you need to 'resilver' your VDEV. Only when all drives have been replaced you will be able to grow the size of your pool.
If you are OK with this approach - and people have used it - it is a way to work around the 'ZFS-tax'.
Not using ZFS is putting your data at great risk!
The BSDNOW podcasts seems to agree with me that if you want true data safety, this 'ZFS-tax' is just the price you have to pay. Either you go with mirrors or you accept the extra parity redundancy.
It is not my goal to steer you away from ZFS. The above is true. ZFS offers something no other (stable) file system currently offers to home NAS builders. But at a cost.
The thing is that I find it perfectly reasonable for home NAS users to just buy a Synology, QNAP or some ready-made NAS from another quality brand. That's what the majority of people do and I think it's a reasonable option. I don't think you are taking crazy risks if you would do so.
If you do build your own home NAS, it's reasonable to accept the 'risk' of using Windows with storage spaces or hardware RAID. Or using Linux with MDADM or hardware RAID. I would say: ZFS is clearly technically the better option, but those 'legacy' options are not so bad that you are taking unreasonable risks with your data.
So using ZFS is the better option, it's up to you and your particular needs and circumstances to decide if using ZFS is worth it for you.